
Golang and local datastores - fast and flexible data storage
Local datastores may not be a fit if you are building a web application that may have more than a single instance and a somewhat rich data schema. But they are an important building block to know if you are looking for real fast temporary storage or can build your own replication.
In this post I will show how I’ve used key/value local databases in Go to
build a database server named Beano that speaks Memcached protocol and can
hot-swap its whole dataset gracefully.
A short taxonomy of Go data storage libraries
I’ve used SQLite, BerkeleyDB and knew about InnoDB but for some reason I’ve never spent as much energy on them as I did on database servers.
But local data stores really made an impression on me when I’ve read LevelDB’s design document; it impressed me how well thought through it was, using SST files and bloom filters to reduce disk usage. The documentation is very practical.
Databases like this offers very little concurrency management - actually very little management tools at all. The database lives in a directory and can be accessed by one process at time.
It’s not anything new: the query pattern is Key/Value: you GET, PUT or DELETE a value under a Key. There is an iterator interface plus some sort of transaction or isolation control.
The taxonomy I use is simple:
- What is the performance profile ? Databases based on variations of BTree will be great for reads, LSM Trees are great for writes.
- How is the data organized on disk ? Single big file or folder ? File wide locking so goroutines can coordinate to write or SST and WAL files that append data and lower the locking burden
- Is it Native Go code ? Easier to understand and contribute to (and frankly I had a bad time with signals while testing bindings to LevelDB).
- Does it implements iterators ? Can I order they keys under some criteria ?
- Does it implements transactions ? Most of them do, but not like RDBMS transactions where you can commit or rollback concurrently. But they are useful for isolation.
- Compactions, snapshots and journaling are interesting features to explore.
Beano: born of a case of legacy
I was working with a set of legacy applications that had performance issues every time new data came in twice a day. The company had a rigorous process and availability requirements, and all applications were written in frameworks that made a change to the database implementation something that could not be done in less than a year. I needed to modify the dataset quickly without changing the main database schema.
All elements in this architecture used a service bus, which had a cache implementation based on Memcached.
We had had a script to warm up the cache by running pre-defined queries and setting the right keys on Memcached, which done wrong would cause a lot of trouble as the database latency was high.
The reason I’ve built Beano is that improving the application using cache was the easiest thing we could do in a short span of time. The data preloaded in Memcached was basically a denormalized version of the main database schema.
But before Beano I’ve tried to implement a way of loading pre-defined
datasets into Memcached and swap them in runtime. It is kind of what you
can do with Redis using the select command.
My first attempt used a Memcached feature that was very new at the time: pluggable backends. I built a LevelDB backend for Memcached, and while at it a meaningless Redis backend.
That worked but not as I wanted mostly because the level of C programming was beyond me. I was learning Go and the idea of implementing parts of Memcached that interested me and coupling with a local database was interesting so I looked at the new tech I was impressed: LevelDB.
After some interactions with non-native LevelDB wrappers, signal issues and wire debugging to learn the memcached protocol I’ve got a server that would switch databases on the fly if you posted to a REST api while communicating through memcached clients or the abstractions I’ve had.
Beano’s internals
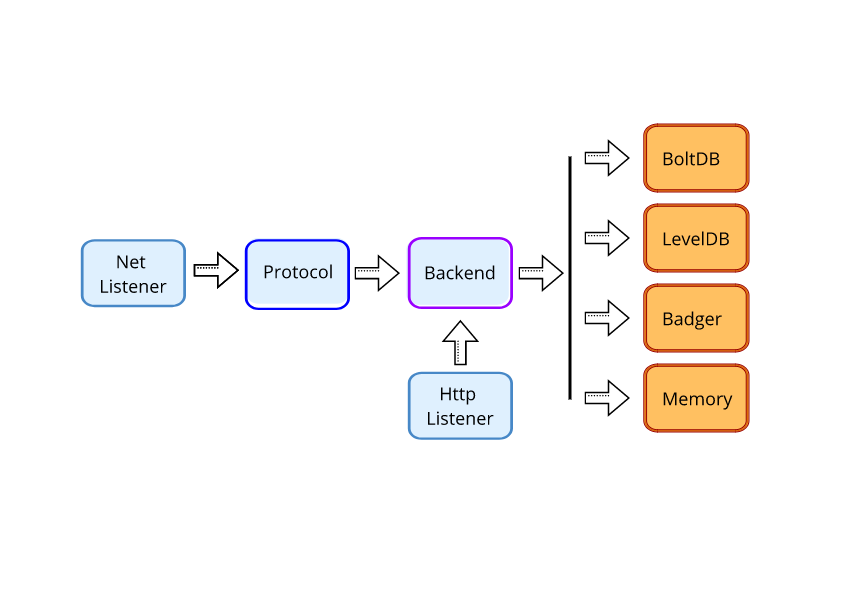
Initially Beano had a single database backend but I’ve found native
Go implementations that I wanted to try. I’ve refactored the server code
to accept pluggable backends through an interface.
|
|
All the operations to be implemented in a new datastore backend are defined on src/backend.go. These functions follow the Memcached protocol loosely. The Memcached protocol parser accepts this interface to execute commands in the backend.
The process which swaps these backends communicates through a channel named
messages in src/networking.go and coordinates with new and currently
active connections.
There is a provision for a new memcached command but currently I’m using
an API route /api/v1/switchdb so this operation won’t require a client
change.
|
|
The only function that knows the implementations of backend interfaces is
the loadDB, in the same file:
|
|
All backends are identified by a name and receive a filename. There is a memory backed backend that won’t use the filename but that’s the information that is passed through the channel so it serves both as signaling to change databases and the path as payload.
There is a watchdog goroutine that receives these messages through the channel
and will prepare the database for new connections, and right after that the accept()
loop that calls the (long) protocol parsing function:
|
|
This is all to separate networking from the backend and implement hot swap. The protocol parsing function knows the backend interface, not the implementation details:
|
|
With that structure we could create a new database with a standalone Beano
instance, populate it with the warm-up scripts, transfer through rsync or
store on S3 to be retrieved later so they can be swapped safely.
Datastores
Each database library has a semantic around transactions and iterators. Isolating them with an interface makes it easier to plug in and test new backends.
Let’s see the GET method on BadgerDB
|
|
Now on LevelDB by means of goleveldb, the library I’ve used:
|
|
There is a comment about levigo, because at some point in time I’ve used
both libraries to provide native and non-native-with-wrapper LevelDB and
compare performance and safety before switching libraries. Some libraries
will return empty if the key was not found, others as BadgerDB have detailed
error codes and all that can be abstracted to match the protocol.
I’ve kept the BoltDB implementation around after it was discontinued and
archived to document what is possible with these abstraction. As I’ve
mentioned before, BoltDB was wrapped under a cache similar to how LevelDB
uses a probabilistic data structure called bloom filter
to avoid disks hits.
|
|
Every time a GET is performed, it has to check if the key was seen.
Same for PUT and ADD - both functions have to load the bloom filter
with the keys they are committing.
|
|
When a read operation is started, instead of going straight for the database
the statement bf := be.keyCache[be.bucketName].Test(key) tests if the
key was added to the cache at some point in time.
Bloom filters are biased to false positives but are trustable on negatives,
meaning that if it never saw the key you could return NOT FOUND safely
while if it saw the key there was a chance of a false positive result
that would force a disk read to check and fetch.
That helped run LevelDB and BoltDB with close performance for reads, while keeping the details local to the BoltDB backend implementation.
I’ve used BoltDB until it was archived and switched to BadgerDB when it got transactions. I recommend going with BadgerDB as the support is great, there is a great community around it.
Conclusion
I’ve shown one case of local data storage but there are interesting
applications out there. For instance connectors that filter and detect
repeated data on streams like segment.io message de-duplication for kafka,
time-series based software as ts-cli
and Dgraph, a graph database in Go.
Beano’s repository is on github - new ideas, issues, PRs are welcome. My plan is to look for new databases and fork the Memcached protocol parsing out of it.
If you like using known protocols to perform specific functions, check my
redis compatible server that only implements PFADD/PFCOUNT using
HyperLogLog: nazare.