
Testing distributed systems in Go
What is etcd
etcd is a key-value store for the most critical data of distributed systems. Use cases include applications running on Container Linux by CoreOS, which enables automatic Linux kernel updates. CoreOS uses etcd to store semaphore values to make sure only subset of cluster are rebooting at any given time. Kubernetes uses etcd to store cluster states for service discovery and cluster management, and it uses watch API to monitor critical configuration changes. Consistency is the key to ensure that services correctly schedule and operate.
Reliability and robustness is etcd’s highest priority. This post will explain how etcd is tested under various failure conditions.
Testing “distributed” is difficult
A distributed system connects multiple independent computing nodes, coordinating work through message passing. This definition is deceptive in its simplicity; Leslie Lamport, inventor of Paxos, offered a more realistic definition, a distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable. Building a stable modern distributed system can be daunting; so many moving parts makes the system inherently complex and ultimately difficult to adequately test.
Naïve system tests assume ideal conditions: the network is stable, machine failures are absent. Production distributed systems are a world apart– machines fail, latencies wildly fluctuate, and network faults are commonplace. A distributed system must still work despite these difficulties. Modeling these failures is extra work but essential. Otherwise, very real bugs will only surface during catastrophic disasters in production.
How etcd is tested
As of December 8, 2016, etcd weighs in at 114,815 lines of Go code. This is only code that could be considered exclusive to etcd; vendored and auto-generated code doesn’t count. Over half the code base, 60,033 lines, is dedicated to tests and testing infrastructure. Since so much of etcd is dedicated to tests, there are many kinds of tests. The testing infrastructure for etcd includes unit tests, integration tests, migration tests, end-to-end tests, benchmarks, regression tests, soak tests, stress tests, and functional tests.
Unit test checks input and output of a single component within the package. For example, raft package passes a message to its message-step function and checks the response.
Client and server interactions are tested in integration tests: start etcd server using unix sockets, send client requests, and check responses from the server.
End-to-end test configures the whole system locally and simulate the real-world operations: set up 3-node etcd cluster with actual etcd binaries, and verify that etcd command line interface is working correctly. These tests are run locally, integrated with our CI systems.
etcd’s “distributed” functional tester
functional-tester verifies the correct behavior of etcd under various system and network malfunctions. It sets up an etcd cluster under high pressure loads and continuously injects failures into the cluster. Then it expects the etcd cluster to recover within a short amount of time. This has been extremely helpful to find critical bugs, before anyone else; see a list of bugs that it has found at GitHub issues for more.
Here’s the overview of functional-tester:
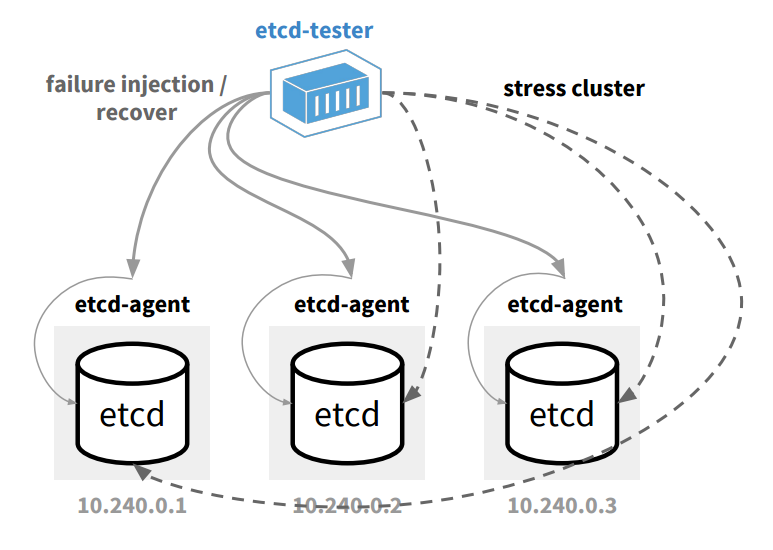
etcd functional test suite has two components: etcd-agent and etcd-tester. etcd-agent runs on each test machine to control the state of target etcd node: start, stop, restart, manipulate network configurations, and so on. etcd-tester runs on a single machine to control the flow of functional tests: trigger agent to stop, start etcd node, inject various failure cases, verify the correctness of etcd under failures.
Some of the failures are:
- Kill random node
- Kill leader node
- Kill majority of nodes in cluster
- Kill all nodes
- Kill node for a long time to trigger snapshot when it comes back
- Network partition
- Slow network
Here’s how etcd-agent kills etcd node:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
func stopWithSig(cmd *exec.Cmd, sig os.Signal) error {
err := cmd.Process.Signal(sig)
if err != nil {
return err
}
errc := make(chan error)
go func() {
_, ew := cmd.Process.Wait()
errc <- ew
close(errc)
}()
select {
case <-time.After(5 * time.Second):
cmd.Process.Kill()
case e := <-errc:
return e
}
err = <-errc
return err
} |
Network partitions can be simulated by manipulating the iptables. Slow networks can be simulated using tc command in Linux operating systems. etcd implements these utilities at netutil package.
Furthermore, it also performs crash tests, such as power loss, I/O error, partial writes, and so on. It is impractical to run these tests with real power failures. So etcd crash testing is simulated with gofail. etcd has tons of fail points in its code base, and tester triggers Go runtime panics in etcd. Some of the failures are:
- panic before/after database commits an entry
- panic before/after Raft follower sends message
- panic before/after Raft leader sends message
- panic before/after Raft saves entries
- panic before/after Raft saves snapshot
- panic before/after Raft applies entries
etcd functional-tester runs 24⁄7; cluster gets about 8,000 failure injections per day, 1 failure injection for every 10-second. In 2016, etcd went through more than 1.7 million failure injects.
Please visit dash.etcd.io for realtime testing cluster dashboards.
Injecting failures with gofail
Here’s example usage of gofail:
1 2 3 4 5 6 7 8 9 |
package gopheracademy import "fmt" func Send() { fmt.Println("before send") // gofail: var beforeSend struct{} fmt.Println("send; success!") } |
And auto-generate the failpoints with:
1 2 |
go get -v github.com/coreos/gofail gofail enable |
Then output would be:
1 2 3 4 5 6 7 8 9 |
package gopheracademy import "fmt" func Send() { fmt.Println("before send") if vbeforeSend, __fpErr := __fp_beforeSend.Acquire(); __fpErr == nil { defer __fp_beforeSend.Release(); _, __fpTypeOK := vbeforeSend.(struct{}); if !__fpTypeOK { goto __badTypebeforeSend} ; __badTypebeforeSend: __fp_beforeSend.BadType(vbeforeSend, "struct{}"); }; fmt.Println("send; success!") } |
1 2 3 4 5 6 7 |
// GENERATED BY GOFAIL. DO NOT EDIT. package gopheracademy import "github.com/coreos/gofail/runtime" var __fp_beforeSend *runtime.Failpoint = runtime.NewFailpoint("github.com/user/gopheracademy", "beforeSend") |
And let’s call this function:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
package main import ( "time" "github.com/user/gopheracademy" ) func main() { for { gopheracademy.Send() time.Sleep(time.Second) } } |
And let’s run this process with failpoints enabled:
1 2 |
go build -v GOFAIL_HTTP="127.0.0.1:2381" ./cmd |
To list failpoints:
1 2 |
curl http://127.0.0.1:2381/ github.com/user/gopheracademy/beforeSend= |
To trigger failpoints:
1 2 3 |
curl http://127.0.0.1:2381/github.com/user/gopheracademy/beforeSend -XPUT -d'panic("sorry!")'
# cmd process will panic |