
Building medical reports in Go
This article is about how we at Mendelics changed our report system from Python to Go using gofpdf library, why we did this change, how we planned it and some insights we got along the way.
Some Context
Before I dive into some technical aspects let me introduce to you guys what Mendelics does. Mendelics is Brazilian laboratory which process DNA analysis in order to find genetic diseases. We use a technique called NGS (Next Generation Sequencing) to process blood samples and at the end of some steps we input all the DNA information into a Go application in a human readable way.
Our physicians will analyse this data and generate a report, basically a PDF file, which will be sent to the patient after a few days.
Our Architecture
Regarding the reports our application was split in two parts:
- Python API which holds patient’s data, exams information and other business logic;
- Go application used by physicians to analyse medical information and “create the report”;
I added quotes into “create the report” because under the hood the Go application just send a POST to the Python API to generate it. At this point the Go application doesn’t know how to create a report at all.
Below there is an image which explain it in a better way.
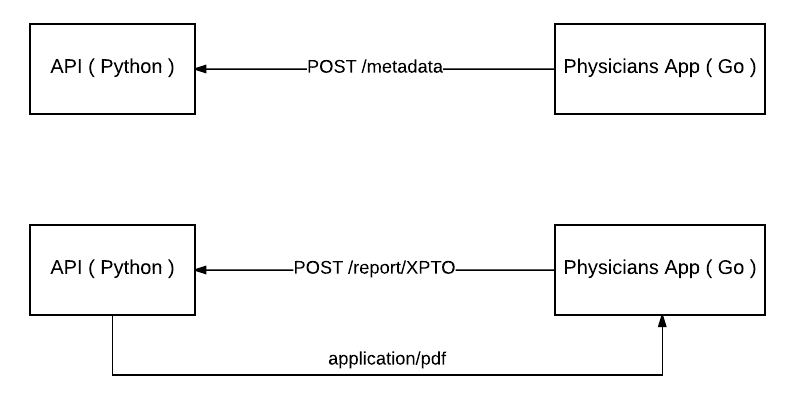
The Python API will use the metadata sent before to create the PDF when the endpoint /report/XPTO is called. In this particular case XPTO is the exam identifier.
Our Problem
The reports was built using Report Lab, a great python library used by players like NASA and Wikipedia, but the way we used it makes changes into report’s structure a nightmare.
Our reports are using background/foreground structure, which maps to a predefined PDF template (background) and the data you wish to add on it (foreground).
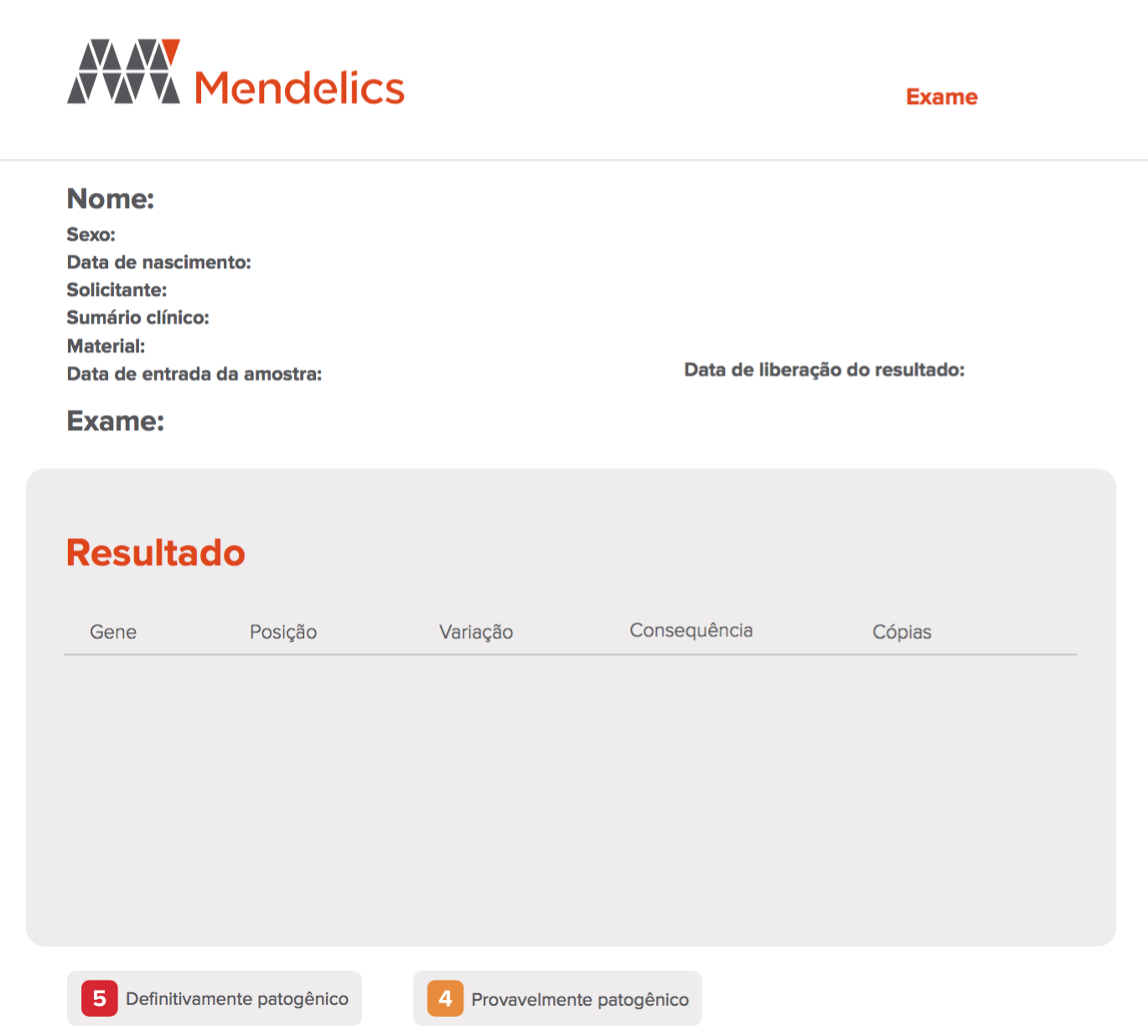
Above you see an example of our background template. It worked for a while, but our requirements changed and our reports got more and more complicated. Everytime we need to add/remove a field, for instance, we need to redesign all those kinds of reports because the foreground data needs to be re-aligned over and over again.
Can you imagine other problems that we had using this approach? Let me list a few:
- Page limit;
- Text limit;
- Tables with prefixed rows length;
- No custom layout;
Our Solution
We want to rewrite it in Go.
Since our main application is written in Go and it’s the only application which needs to know about reports why not to move report’s logic to this end? It’s makes sense, but is there any good Go library out there which is easy to use and handles our known problems in a good way?
The answer is gofpdf.
A great library ported from PHP which have good support for everything we needed at this time. So let’s plan this change.
Proof of Concept
We’ve created a new repo to check if we could reproduce the hardest report using gofpdf and to understand the trade-offs with this new approach.
To start we need to get it as any Go library using go get github.com/jung-kurt/gofpdf
With the library downloaded, the code to create our POC is very simple.
We created a function NewReport and inside of it we configured how this document will looks like (e.g. font family, font color, page size, header and footer data). Let’s look into it:
|
|
Our struct Report just holds the configured document as you can see in the last line before actually return it.
The idea here is just to show how simple is to create your documents using this library. You could check the docs to understand what each function does. Let’s move one step further.
The main code lives in a HandleFunc, which was created just to be able to see this PDF using a browser instead of generating it in the file system.
|
|
Each function in the report object (created by our NewReport as we saw above) is a section builder for that given name. We build the patient header, with information like name, age, etc, diagnostic section which is where we explain if the patient has a positive or negative result for that specific exam and so on.
Let’s get the Method function to see how it works under the hood.
|
|
We just set the font size for that section, build a text for it and add it to the document using the MultiCell function. Easy! No x/y alignment, text limit, etc. The library will handle it based on our previous configuration at NewReport.
Going back to the main function, at the end we write the final document back to the ResposeWriter and we’re done!
Below you could see the result of this POC: a report 99% similar to what we have in python in just 351 LOC:

From Python to Go
As we saw previously, we need to change how Python and Go communicate with each other. Instead of sending an application/pdf as before, now the python API needs to serve all the data needed to construct the report on the Go side.
We created a new endpoint to serve this new information as we can see below:
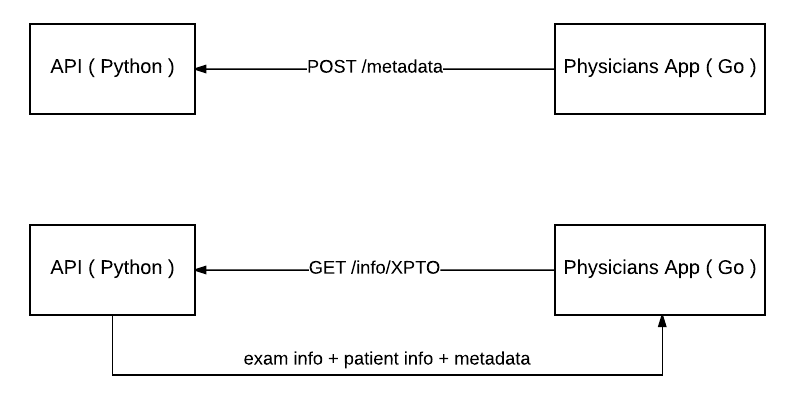
With the API ready we changed how our Go application called it. Instead of calling the API to build the report now we’re calling the model endpoint in order to get the metadata necessary to construct it in our end.
|
|
After that we pass this data to our report object:
|
|
Did you see how this code is very similar with the one from our POC? Yes, you got this right, we just basically copy&paste these code from POC to our application and just remove the hardcode part related to how we build each section. The Output function is pretty much the same:
|
|
Bonus: Unit Test For PDF
Your methods to build each PDF’s section are fully tested, but what if I change something like font color, an image position or another visual thing? How can I get feedback about it?
In our case, let’s say we change accidentally the color of an arbitrary element. The right document was:
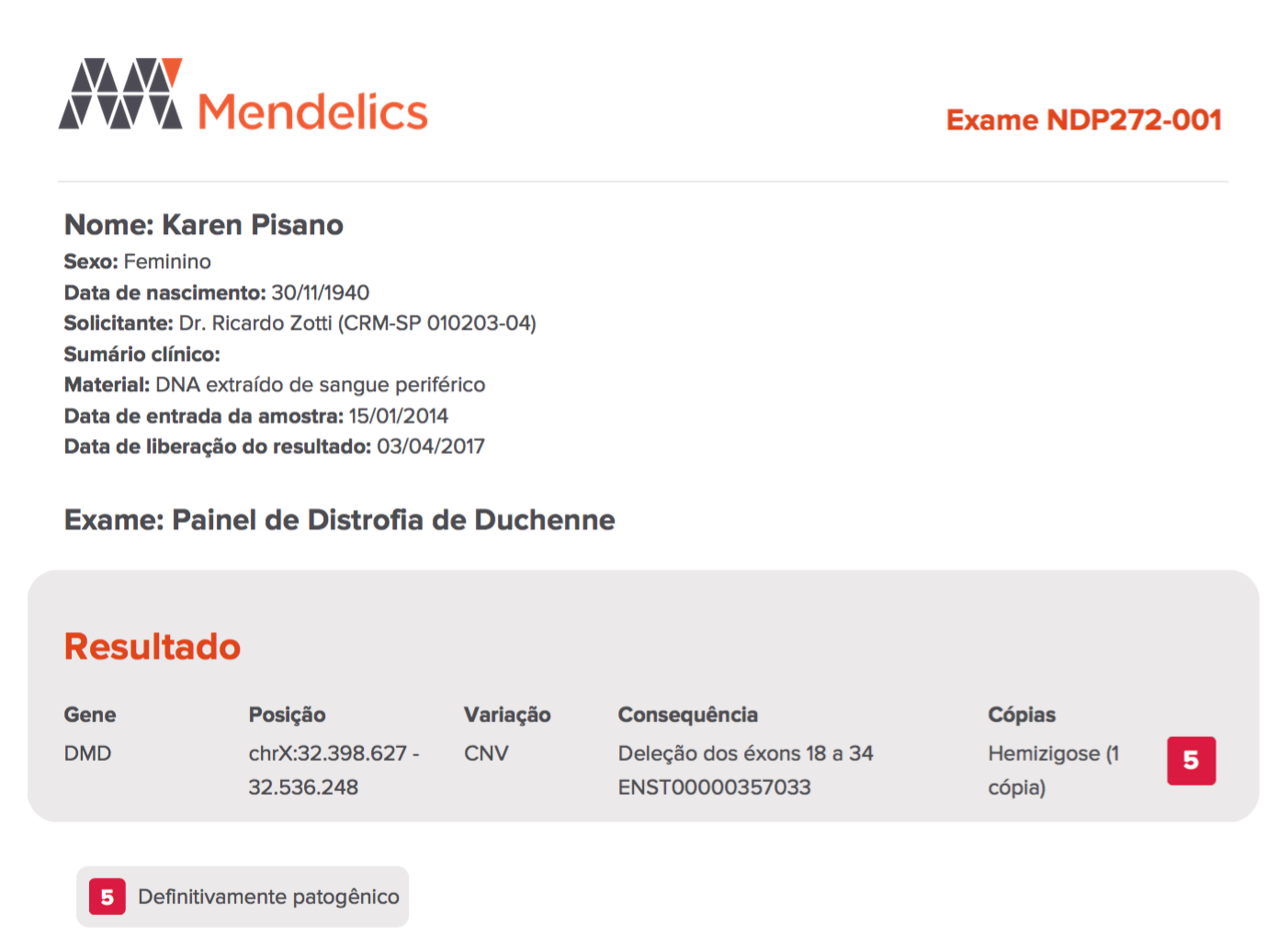
and now it looks like this:
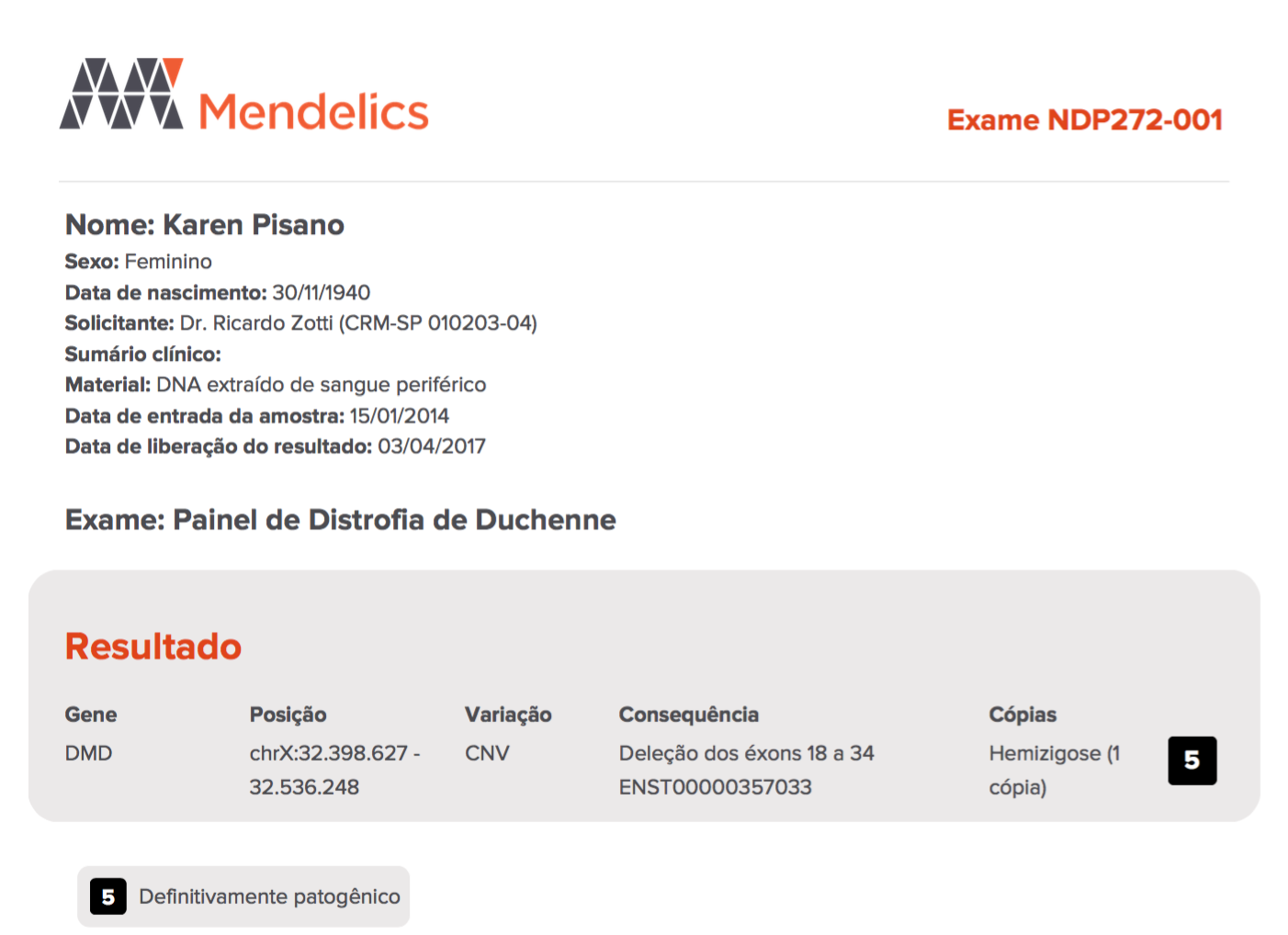
The Mistake
We changed the background color of an element in the right corner.
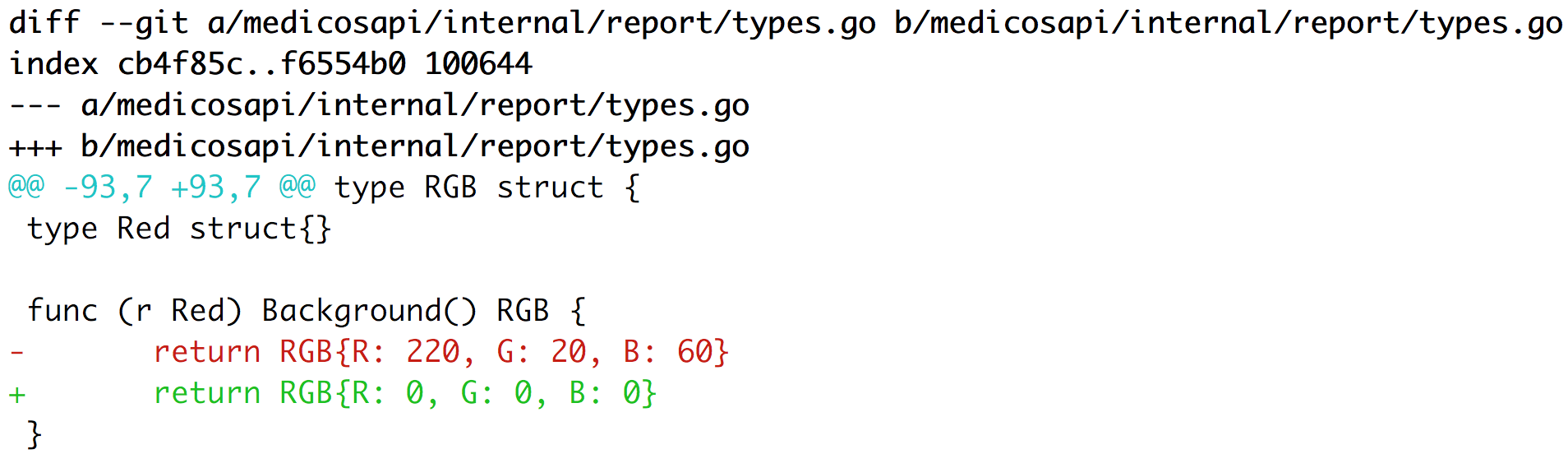
Without any unit tests we need to check all documents by eye to guarantee we didn’t break anything, but the library provides an awesome way to test our PDF files! Please check the unit tests inside the library to get the whole idea.
In our end our tests will alarm if we made a mistake like above:
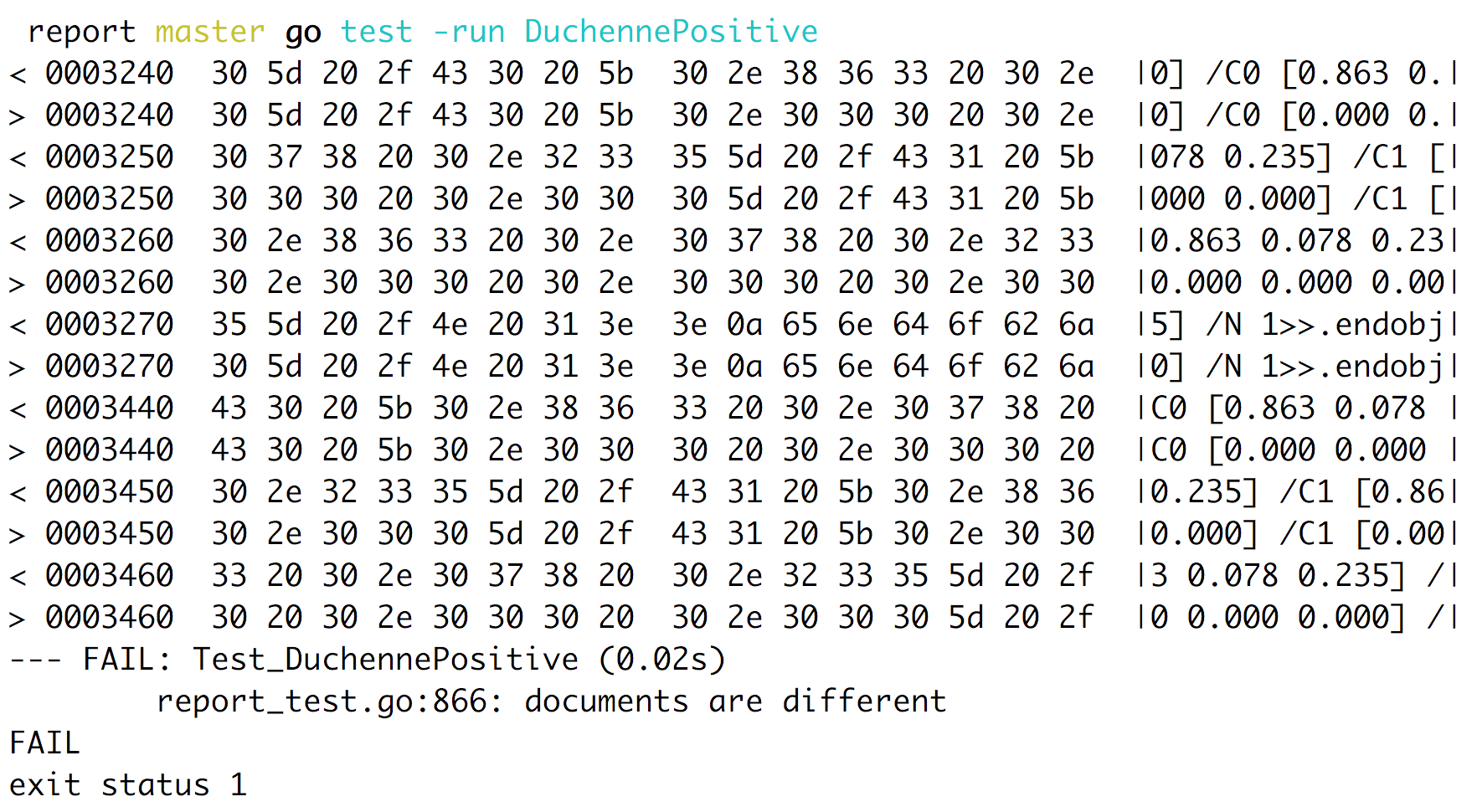
Conclusion
I strongly recommend to you gofpdf if you need to build PDFs in Go.
Also today we can create any kind of project using Go not limited to CLI and APIs and even code that doesn’t need to rely on channels and goroutines to get the job done.
I’m very happy with the Go ecosystem so far and looking forward to see what the community can build using it.